● 作者/政治不正確
當兩本論文有大幅雷同,我們如何確定是A抄襲B,還是B抄襲A?其中一種方式,就是檢查一致性(coherence) :把雙方雷同的部分,放在各自的論文中,與其他不雷同的部分,是否在邏輯與特徵上一致。
就像某首爾大學法律系第一名畢業的律師提醒我們:不能因為看到一條雌抹香鯨吃了大王魷魚後,排出了1.5公噸的卵,就推論抹香鯨是卵生動物。我們可以應該去查卵的DNA,看這些卵哪來的。
陳明通呼籲大家不要去賣肉。可以。我們就回到研究脈絡本身來看。
辨認抄襲者是林還是余,需要一點統計知識,因為雙方都是用統計從事分析,使用的還是完全一樣的統計模型:完全一樣的迴歸式與完全一樣的迴歸變數。連對這些模型的描述,文字也都雷同。
問題是,他們兩個的「研究架構」並不相同:當中「獨立變項」有部分相同,「中介變項」則是完全不同。所以在這個余林完全相同的統計分析模型裡,中介變項的角色,符不符合原本的研究架構,是相當好的辨識工具。也就是說,我們可以藉由「中介變項」這個統計模型中的DNA,去判斷余林雷同的分析模型,到底是從誰的研究架構而來,從而判斷是誰抄誰。
統計分析有一套邏輯與程序。不同的研究架構或推論架構,統計模型中的變數選取與迴歸式構建方式絕對會有所差異,拼拼湊湊的研究一定看的出來。而任何對統計分析稍有認識的人都能看出:余林兩人完全一樣的統計模型,是從余正煌的研究架構來的,不是林智堅的。
來看這個兩人雷同的統計模型「二元勝算模型」(余論文頁58,林頁52,如下圖一)。這個勝算模型包含了兩個迴歸式:模式一與模式二。其中,模式二所選取的「自變數」(表格中最左邊那一欄),是模式一的自變數(性別年齡教育程度地區族群)再加上「藍綠陣營」「欣賞候選人」及「為新竹帶來改變」三個變數。
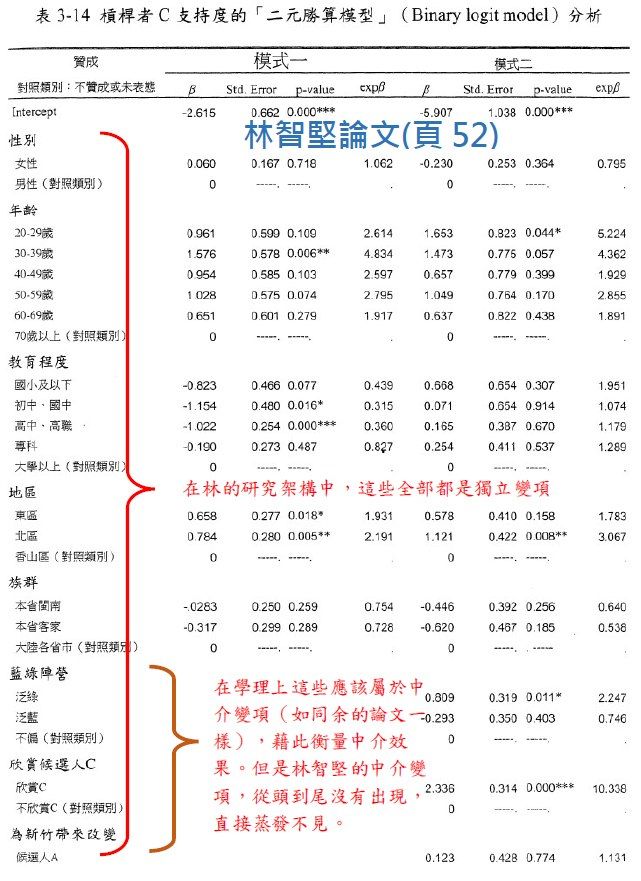
▲圖一:林智堅論文的研究方法之統計模型。(圖/政治不正確臉書粉專提供)
這種設計的主要目的,就是藉由比較模式一與模式二這兩個迴歸式的結果,去判定「藍綠陣營」「欣賞候選人」及「為新竹帶來改變」這些模式二的新增變數,所帶來的中介(mediation)效果。
比如說林智堅對模式二的分析(頁50)中說:「……『教育程度』變數會透過所選取的政治社會心理變數完成解釋,但是『年齡』及『地區』 仍保有獨立的解釋能力」
這句話就是在分析政治社會心理變數帶來的中介效果。而這些政治社會心理變數(藍綠陣營﹑欣賞候選人﹑為新竹帶來改變)就叫做中介變項(mediators)。
余的論文也有相似的分析(頁56)。但是智堅,你提到這些政治社會心理變數,是余正煌的研究架構中提出的中介變項(余論文頁8),而不是你的。你自己研究架構提出的的中介變項,是「洪仲丘事件」「太陽花學運」「對馬政府的不滿」。(林論文頁7,下圖二)
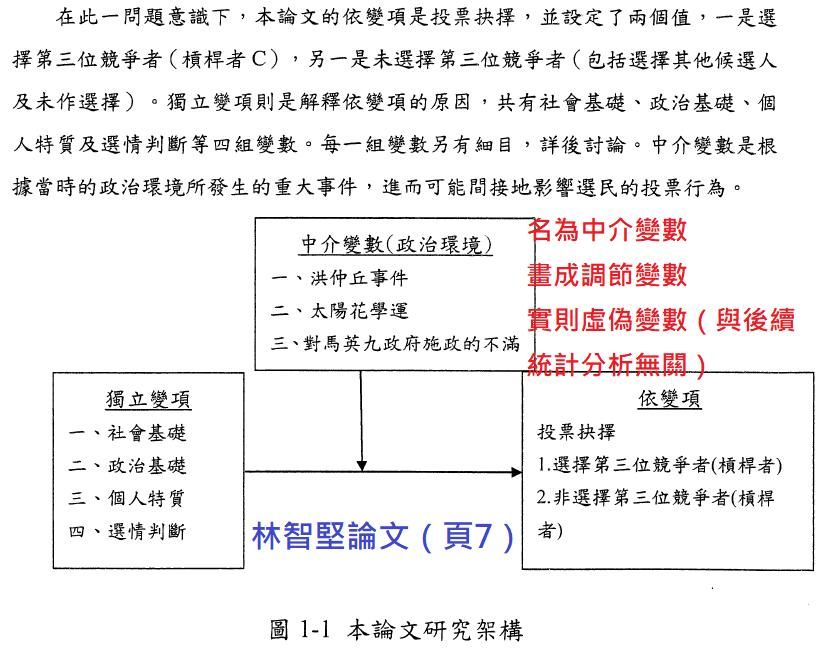
▲圖二。(圖/政治不正確臉書粉專提供)
根據林智堅的研究架構,不應產生跟余正煌一模一樣的「二元勝算模型」。就像鯨魚不會產卵一樣。而林智堅的二元勝算模型,其DNA「中介變項」卻是來自余正煌的研究架構,這就叫研究脈絡。【註一】
台大社科院如果連這麼明顯的馬腳都看不出來,其學術水準保證遭人恥笑。畢竟利用中介變項是非常非常非常流行的分析方法(我說了幾次非常?),國內外使用過的學者很多,超級多。做民調的游盈隆,還曾經拿「關鍵性中介變數」來比擬台灣【註二】。
「分析模型」與「研究架構」對不起來,就好比「實驗設計」與「研究目的」對不起來,是嚴重的致命傷。就算沒有抄襲問題,也足以讓林智堅論文不及格。更何況,其錯誤的分析模型,對應的居然是余正煌研究架構,而不是林智堅自己的。兩者相加,台大若是撤銷林的學位,是非常合理的處分。
【註一】陳明通每次解釋余林兩人的研究脈絡,都會技巧性地迴避提及「中介變項」。只專注在兩人論文中「獨立變項」與「依變項」的異同。國民黨居然對此也渾然不覺。難怪民進黨每次凹起是非來,總是肆無忌憚。
【註二】游盈隆「游盈隆觀點:台灣可以是關鍵性中介變數」
熱門點閱》
► 鍾文榮/本來無一物 審計部打臉五倍券消失的八百億元經濟效果
► 裴式旋風遠離亞太餘波盪漾 星學者:中能威脅台海也能恫嚇南海
●本文獲授權,轉載自政治不正確臉書專頁。以上言論不代表本網立場,歡迎投書《雲論》讓優質好文被更多人看見,請寄editor88@ettoday.net,本網保有文字刪修權。





我們想讓你知道…我們可以藉由「中介變項」這個統計模型中的DNA,去判斷余林雷同的分析模型,到底是從誰的研究架構而來,從而判斷是誰抄誰。